作为一个分布式异步计算框架,Celery虽然常用于Web框架中,但也可以单独使用。常规搭配的消息队列是RabbitMQ、Redis。
目录结构
1 | $ tree your_project |
其中celery.py是主文件,定义celery app,config.py是celery的配置,tasks.py 是异步任务的具体实现。
celery.py文件内容
1 | from __funture__ import absolute_import |
config.py文件内容可参考下一节
tasks.py文件内容
1 | from __funture__ import absolute_import |
运行命令
1 | nohup /usr/local/python3.6/bin/python3.6 -m celery worker --loglevel=DEBUG --app=${PROGRAM_NAME} --queues=$1 --hostname=$2 --pidfile=$3 1>/dev/null 2>/dev/null & |
其中运行可参考后续章节。
运行原理
一次Task从触发到完成,序列图如下:
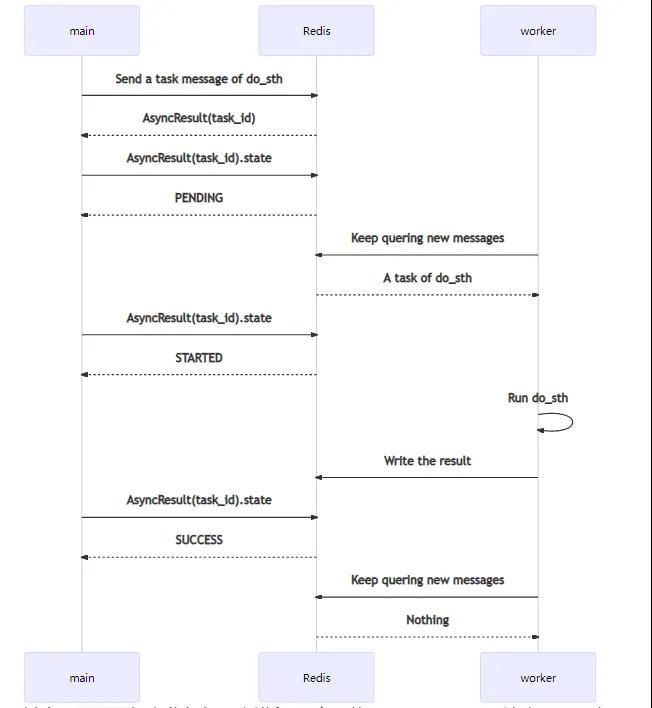
其中,main代表业务代码主进程。它可能是Django、Flask这类Web服务,也可能是一个其它类型的进程。worker就是指Celery的Worker。
main发送消息后,会得到一个AsyncResult,其中包含task_id。仅通过task_id,也可以自己构造一个AsyncResult,查询相关信息。其中,代表运行过程的,主要是state。
worker会持续保持对Redis(或其它消息队列,如RabbitMQ)的关注,查询新的消息。如果获得新消息,将其消费后,开始运行do_sth。
运行完成会把返回值对应的结果,以及一些运行信息,回写到Redis(或其它backend,如Django数据库等)上。在系统的任何地方,通过对应的AsyncResult(task_id)就可以查询到结果。
celery task的状态
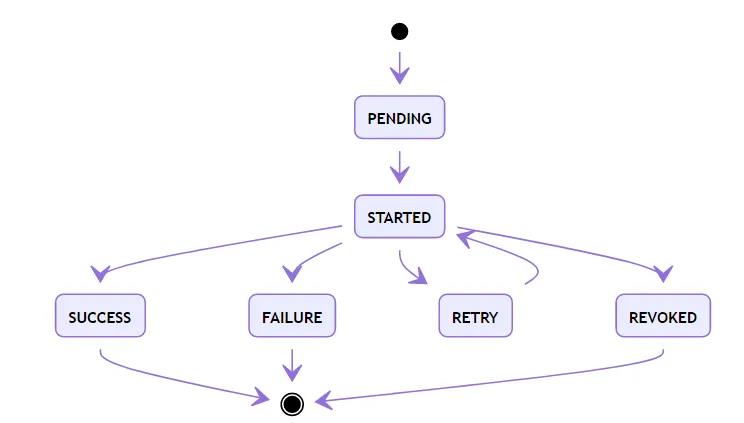
其中,除SUCCESS外,还有失败(FAILURE)、取消(REVOKED)两个结束状态。而RETRY则是在设置了重试机制后,进入的临时等待状态。
另外,如果保存在Redis的结果信息被清理(默认仅保存1天),那么任务状态又会变成PENDING。这在设计上是个巨大的问题,使用时要做对应容错。
celery常用配置
1 | # 指定任务接受的内容类型(序列化) |
更多配置参数请移步Configuration and defaults
worker命令行参数
1 | Global Options: |